

















Semantic database
A little bit of history
Data base term was introduced for the first time in 1963 by Kenneth Swanson in a technical memo bearing the title of "Development and Management of a Computer-centered Data Base" [1]. In the early 1970s the two words were linked together to form the well-known neologism database. By the way, the first database management system was developed in the 1960s. The first database models were the network-based and the hierarchical one. The latter was adopted by IBM as the foundation of IMS. It was an IBM researcher, Edgar Frank "Ted" Codd, to define in 1970 the relational model [2], but the first IBM commercial product based on that model appeared only in 1980. Since relational one, no new model was developed. Of course, researchers continued to improve the database concept by introducing distributed databases, object-oriented databases and — recently — XML and hybrid databases, as version 9 of IBM DB2, but all those databases can be implemented by adding new features to a relational database, so there was nothing new in modeling since 70’s (for further information on databases, you can look at Wikipedia).
About relationships
In real life everything is connected to the rest of the world by relationships. Each object, creature, individual, event, is related to other objects, creatures, individuals, and events in some way. You may have more than one relationship between two elements as well as the same relationship may exist between one element and several other ones. Furthermore a relation could be represented in many different ways. In real life we use natural language to express liaisons, but even if natural language is a very flexible way to communicate, it is also an intrinsically ambiguous and multiform way to represent concepts. For example, I can say that "George is Mary’s husband" as well as "George is married with Mary". Of course, if George is married with Mary, Mary is also married with George. This is quite obvious in case of marriages, but it is not necessarily the case for any relationship. Furthermore, even if "Mary is married with George", Mary is not George’s husband but George’s wife. Generally speaking, relationships are not a well-defined set with a clear set of operators as traditional math sets. Of course, if you focus on a specialist niche with a technical jargon, you can define a formal way to describe objects and the corresponding relationships, but this is not true in general. Therefore, if you want to describe relationships so that they can be understood by an information system, you should develop specific techniques.
A new database model
A semantic database is a database where a number of objects are connected each other by semantic relationships. You can represent it as a graph where the nodes are the objects and the links are the relationships. It is important to point out that both elements and relationships are elements of the database. So, differently from a hierarchical or relational database, the database structure and the database content are not two concepts to be kept quite separate from each other, but they are intrinsically correlated. As I add new objects I also introduce new links, so I change both the content and the structure.
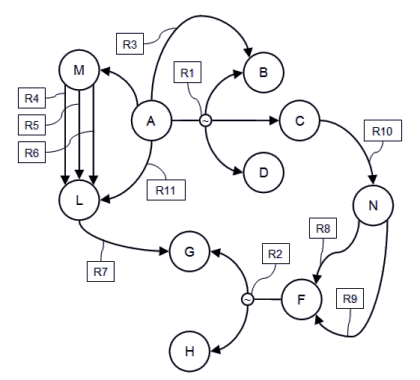
Network representation of semantic database
So I can query both objects and relationships, as well as any logical combination of both. For example, I can search for all married people, or for all men who married a woman whose given name is "Mary", or simply count how many marriages lasted more than 7 years, or how many people married at least twice.
But how do I implement such a database? First of all, how do I represent relationships? Representing objects is a well known problem. An object is just a set of data which could or could be not encapsulated in methods. The simplest object is just a pair {name, value}, but of course I could have more complicated structures, arrays, matrices, enumerations, plain or rich text, multimedia objects. Furthermore they can be simply named data or encapsulated data, that is, real objects. So each object could provide both class and objects methods. In any case they must be real objects, not abstract classes. If I want to store an abstract class, I have to create an object which represents the class. But what about relationships? By definition I cannot use objects methods, since I want to keep separated objects and relationships. Furthermore I may have several kind of relationships: one to one, one to many, many to many. I should be able to represent all of the, in theory. Of course I could constraint my database to use only one to one relationships, but developing also other topologies would allow me to optimize the implementation.
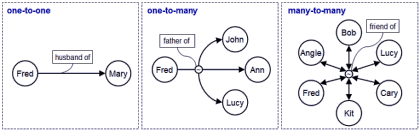
Relationship topologies
In theory describing a relationship is just a matter of relating objects. If each object is represented by a Universally Unique Identifier, a one to one relationship can be represented by a structure containing the UUID’s of the two related objects. Of course, the relationship itself will be identified by an UUID. Since we are representing a semantic relationship, anyway, we should include also semantic info that can be understood by both machines and human beings. First of all we should be able to distinguish between elements which act as objects and elements which act as relationships. So we should use a flag to distinguish them, and possibly use the same flag to distinguish among different kind of relationships. Second, we should ensure that the relationship is well-defined from the semantic point of view. Note that a semantic relation is not necessarily commutative, that is, order may matter. Furthermore a relationship could be expressed in many different ways and languages too.
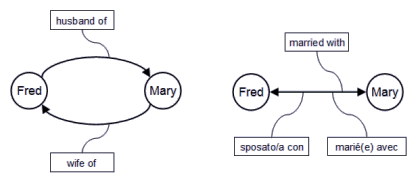
Different ways to represent the same semantic relationship
For example, if "Fred is the father of Ann and John" is true, it is also true that "Ann is Fred’s daughter" and "John is Fred’s son", but "Ann is Fred’s son" is obviously not true. If you also take in consideration the intrinsically ambiguity of natural languages, representing a semantic liaison in such a way it can be understood by a machine is really a challenge. Real world is quite complicated. For example, recently it was demonstrated that a baby can be generated by using the DNA of two women and one man, so it would generate a challenging set of relationships if we apply standard concepts… Anyway, how to effectively represent semantic relationships is out of the scope of this article. Several techniques to integrate semantic relationships in object-oriented databases [3] and knowledge systems [4] have been already proposed and implemented in the last ten years.
Another important question is: "Is it really a semantic database different from a relational one?", that is, it is possible to implement a semantic database by using a relational model? Am I really defining a new model or am I just describing a variant of an existing model? Well, in a relational database we relate values by using fields. For example, "Ann is Fred’s daughter" can be represented by setting Ann value in DAUGHTER field of Fred record:

A relationship in a relational database
However this mechanism does not easily allows to add a new relationship, since I have to change the record structure. Furthermore, if I change that structure for Fred, I change it also for Frank, Mary and any other record representing a potential parent. But what if I called the relation FATHER OF rather than DAUGHTER? If the table contains Mary too, I have that "Mary is the father of Ann". So I have to parcel out Mary’s record from the table and create a new table. Furthermore, the fact that I am storing the information that Fred is Ann’s father does not mean that I am interested to store the same info also for George or other guys in the same table. So, by adding more and more relationships to my database I risk to have a table for each record. In practice, the structure of a semantic database continuously changes as its content changes. I could probably represent a semantic database by using a relational implementation, but it is surely not the most efficient way. So, a semantic database will probably require a new physical implementation in order to facilitate and speed up access to data and relationships, editing, and queries. This is out of the scope of this article too, but surely we have the technology and the architectural competencies to develop it. About advantages, it is my opinion that availability of semantic information will be more and more requested in the next few years, so time is ready for semantic databases.
Bibliography
- [1] Swanson,A. Kenneth, "Development and Management of a Computer-centered Data Base", Technical Memo, 1963, System Development Corp., Santa Monica (CA)
- [2] Codd, E.F., "A Relational Model of Data for Large Shared Data Banks", "Communications of the ACM" 13 (6): 377-387
- [3] Li-Min Liu, and Halper, M.m, "Incorporating Semantic Relationships into an Object-Oriented Database System", System Sciences, 1999, HICSS-32, System Sciences, 0-7695-0001-3
- [4] Tawil, A.-R. H., Gray, W. A., and Fiddian, N. J., "Discovering and Representing InterSchema Semantic Knowledge in a Cooperative Multi-Information Server Environment", in "Database and Expert Systems Applications", 2000, Springer Berlin/Heidelberg, 978-3-540-67978-3

Ad oggi, la vera sfida dell’informatica nel mondo del World Wide Web sono i motori di ricerca semantico-relazionali. Più delle reti neurali, i motori semantico-relazionali sarebbero in grado di individuare le relazioni semantiche tra le pagine delle rete, definire metadati in grado di rappresentarle, estrapolare gli argomenti di una conversazione su di un blog, individuare gli opinion leader, ecc.
Sono convinto che linguaggi come il Prolog, basati sulla programmazione logica e la rappresentazione logica di concetti, predicati e relazioni tra di essi, siano almeno concettualmente quanto più si avvicini ad una base di conoscenza fondata sulla semantica delle relazioni e non più sulle relazioni tra tuple di dati, o anche i vecchi dbms legacy di tipo gerarchico.
LP
Sono perfettamente d’accordo sui motori semantico-relazionali, ma questi in genere operano su dati non strutturati, come ad esempio i testi. Le basi dati sono invece dati strutturati. Il modello semantico ha in effetti lo scopo di memorizzare relazioni semantiche strutturate che possano poi essere utilizzate da altre applicazioni per vari motivi, inclusa l’interpretazione di dati non strutturati e la definizione di un contesto che possa essere utilizzato appunto dai motori semantico-relazionali.
Ivan Herman, W3C Semantic Web Activity Lead, indicated to me a couple of interesting pages about triple stores, that is RDF Triple Store Systems and ESW Wiki: LargeTripleStores.
According to Ivan’s understanding, some of these are implemented on top of relational database systems, some of them are developed as triple stores from bottom up, for example Kowari and derivatives. He thinks that it could be the case of Jena SDB and Sesame, too.