

















Web 2.0 Orientation Map
In one of my latest articles, I proposed a definition of Web 2.0 which focused on human relationships from a social point of view, and on service-oriented architecture, from a technological perspective. Of course, such a definition cannot explain in detail a diversified and complex world as Web 2.0 is. As Tim O’Reilly said in a very interesting article, Web 2.0 is characterized by many distinctive peculiarities. In particular, the most important two are probably the new role of users and the continuous development of code. In Web 2.0, in fact, users are no more simply consumers but prosumers, that is, providers and consumers at the same time. On the other hand, Web 2.0 applications improve in proportion to how much people use them. This is why they are always in a beta stage of development. But how do they improve? Well, in most cases they still improve because the development team traces how people use the applications, participates to debates about problems, wishes, and criticisms, and continuously changes the code to make them better and better. Applications as Flickr or LinkedIn improve in that way. However there are other cases where users are directly involved in improving the Web 2.0 application by changing the code. A typical example is Mediawiki and wiki’s in general. In most wiki’s, people does not only generate content, but develop templates and extensions which provide other users with continuous new functionalities.
So we can say that a Web 2.0 application is made of two components: a content and a container. The content consists of all data and pieces of information available thru that application. The container is the object that allows people to access that content. So a container is made of one or more interfaces and a set of services. The interfaces allow both people and other applications to access the services. In case a service is accessed by another application, it usually occurs through specific protocols. In some case this is true for people too. For example, the request to log in to access specific sections of a Web 2.0 application is a protocol in all respects.
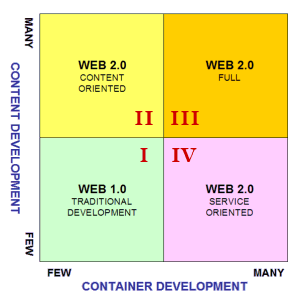
Web 2.0 Orientation Map
So, a direct consequence of this breakdown structure is that each Web 2.0 application can be represented in a map where we show evidence of how many people are involved in content and container development. This is really true for any web application, but most of traditional web development is constrained in the first quadrant of the map (bottom-left). Let us consider in fact a classic Web 1.0 application as a traditional site or a portal. In a traditional site, the same development team is responsible to generate both the content and the container, that is, the site itself as a whole. It is the classic turnkey site, where the customer is involved only to provide requirements and to supply the raw material to be used to generate site content. A portal is not so different. In a portal, the development team provides the customer with a container with a complete set of services, inclusive of the authoring ones. It is the portal owner himself which continuously generates and update the portal content. Even in this case, however, there is an editorial staff who is responsible for that activity. Therefore, in both cases there are few people who design and implement the container as well as few people who generate the content. If they are the same team or not, it does not matter.
Let us move to the second quadrant (top-left). The container is still responsibility of a relatively small group of individuals, but the content is the result of the work of many people. This is the typical case of a blogging platform or social networking tools like LinkedIn, YouTube or Shelfari. Most Web 2.0 applications lie in this quadrant. There are still few who developed the Web 2.0 application and continuously improves it according to user needs and habits, but all the content is practically generated by many, that is, the users themselves. Even when the blogging platform is based on open source code, the number of developers is much lesser than the number of people using that platform and publishing content.
The third quadrant (top-right) is in my opinion the fulfillment of the Web 2.0 concept: both content and container are the result of the work of many people. This is mostly true for a wiki, since people not only continuously publish content but improve the wiki itself by developing new templates and extensions, even if the number of wiki administrators is relatively small. There are not many Web 2.0 applications in this quadrant, since co-developing containers is quite more difficult and requires more discipline than co-generating content, but it is surely the most exciting area for highly valuable Web 2.0 applications. An example is Wikipedia.
The fourth quadrant (bottom-right) is where most of content is provided by few individuals, whereas many people are continuously developing new ways to take advantage of it. There are still very few applications of this kind: it is mostly an unexplored world. In general, there could be many reasons why content comes from few sources: for example, those specific data could be quite difficult to obtain, or they may require specialized or professional skills, or must be provided by law by highly reliable sources. We can imagine applications which are based on data provided by government agencies or by newspaper publishers. For example, a major daily newspaper may decide to make available its archives to everybody. By taking advantage of such reliable data, it is possible to develop many interesting Web 2.0 services which would allow to cross data with other pieces of information, to generate reports and statistics, and to perform business intelligence activities. Everybody could add new functions, graphical representations, export services for various data formats, but the providers of content would be a limited and trustable set of sources.
So, this is in my opinion the Web 2.0 Orientation Map, a framework representing any Web 2.0 site according to how many people was involved in developing both content and container. Of course, it is not an exhaustive or definitive way to represent and map Web 2.0 sites, but it is intended to provide an interesting perspective to easily classify Web 2.0 sites according to the way they arose and evolve.

Si prega di usare Facebook solo per commenti brevi.
Per commenti più lunghi è preferibile utilizzare l'area di testo in fondo alla pagina.
Commenti Facebook